
1. 서론
인터넷과 소셜미디어의 발전으로 인해 사람들은 일상생활에서의 경험을 사진과 글을 쉽게 공유하고 있다. 2021 네이버 블로그 리포트에 따르면 포털사이트 네이버(https://www.naver.com)에서 운영하는 블로그(Blog)에는 하루에 평균 87만 개의 게시글이 올라오며, 이 중 많은 게시글이 장소와 경관에 관한 내용을 담고 있다. 독일의 온라인 데이터 통계 사이트인 Statista에 따르면 2022년 전 세계적으로 4억 5천 9백만 명의 사람들이 인스타그램(Instagram), 페이스북(Facebook), 왓츠앱(WhatsApp) 등의 소셜미디어를 사용하고 있는 것으로 나타났다. 미국의 데이터 분석 회사인 DOMO에서 발표한 2022년 자료에 의하면 인스타그램에서는 분당 6.6만 장의 사진이 업로드되고 있는 것으로 나타났다. 이는 매일 약 1억 장의 사진이 인스타그램에서 공유되는 것이다.
소셜미디어에 게시되는 게시물들은 사진을 비롯하여 해시태그(hashtag)나 짧은 글과 함께 게시된다. 사진이나 해시태그를 통해 사람들은 장소나 경관에 대해 느끼고 생각하는 것을 표출한다. 이용자들의 인식과 요구를 분석하는 조경 분야에서 소셜미디어 데이터는 분석을 위한 많은 양의 표본이 될 수 있으며, 분석 가치를 가지고 있다. 최근에는 이러한 소셜미디어의 게시글과 사진을 활용해 관광객들의 인식을 평가하여 관광자원을 계획하거나(이혜진 등, 2019; 조나혜 등, 2019), 텍스트와 사진을 함께 분석하여 섬 지역의 경관 인식과 특성을 파악(도지윤과 서주환, 2021)하는 등 다양한 연구들이 나타나고 있다.
기존 경관 분석 방법은 주로 설문조사나 인터뷰를 통해 경관 인식 평가를 진행하고 이를 분석한다. 이 경우 대규모의 평가집단을 모집하기 어려우며 시간과 비용이 많이 소요된다. 하지만 소셜미디어의 사진 데이터를 활용한다면 이를 보완할 수 있다. 본 연구에서는 대량의 소셜미디어 사진 데이터에서 힐링장소의 경관을 분석하기 위해 합성곱 신경망(convolutional neural network, CNN)을 이용한 딥러닝(이하 ‘CNN 딥러닝’이라고 한다)을 사용하여 경관 이미지를 분석하는 과정을 소개하고, 경관 이미지 분석을 위한 CNN 딥러닝 모델이 적합한지 평가하고자 한다.
경관 이미지 분석을 위해 설정한 연구의 대상은 힐링장소의 경관이다. 최근 사회경쟁, 업무의 고도화로 인한 스트레스, 1인 가구 확산 등 사회현상과 2020년 코로나19로 인해 실내 생활이 잦아지면서 힐링에 대한 관심이 증가하고 있다. 힐링에 대한 대중들의 관심과 필요가 높아짐에 따라 힐링을 콘셉트로 한 다양한 장소의 계획, 설계안이 나타나고 있다. 하지만 힐링은 개인이 자라온 환경이나 가치관, 성향에 따라 그 기준과 이상향이 다르고 주관적이므로 개념을 규명하기 어려운 대상이다(유현배, 2018). 따라서 형태가 모호하고 개념이 객관화되지 않은 힐링장소의 인식을 CNN 딥러닝을 통해 표준화해 보고자 한다.
2. 이론적 고찰
딥러닝은 이미지 인식, 음성 인식, 자연어 처리 등 여러 분야에서 놀라운 발전을 이루고 있다. 딥러닝은 인간의 뉴런(neuron)을 모방한 인공신경망(artificial neural network)을 기반으로 한 심층 학습법으로, 다양한 계층의 신경층을 통해 대상의 특징점을 학습하고 사람의 뇌와 비슷한 방식으로 기계가 스스로 학습할 수 있도록 한다. 그중에서도 CNN 딥러닝은 시각적 이미지 분석에 특화된 구조로 되어 있어 글자, 숫자, 고양이, 사람, 자동차 등의 객체를 인식하고 분류하는 데 뛰어난 성능을 보인다. CNN 딥러닝은 LeCun et al.(1989)이 우편 서비스에서 손 글씨 숫자 인식을 위해 처음 제안한 알고리즘으로부터 발전되었다. CNN 딥러닝의 구조는 입력 이미지의 특징을 추출하고 범주(class)를 판별하기 위해 합성곱층(convolution layer, CL), 풀링층(pooling layer, PL), 전결합층(fully connected layer, FCL)의 세 가지 주요 과정을 거친다(그림 1 참조).
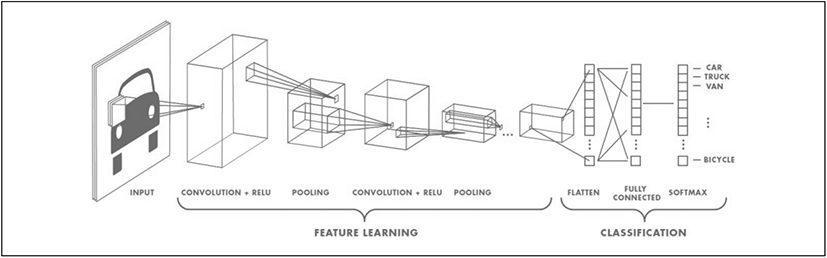
CNN 딥러닝의 핵심은 합성곱 연산(convolution)과 풀링 연산(pooling)이다. 합성곱 연산은 전체 이미지에서 특정 영역의 특징을 필터링하는 방식으로 진행되며, 풀링 연산은 결과물의 특징을 강조하고 이미지의 크기를 줄이는 방식으로 진행된다. 마지막으로 전결합층에서 최종적인 분류 작업을 수행한다. 정리하자면 CNN 딥러닝은 여러 번의 합성곱 연산과 풀링 연산을 반복하여 이미지의 특징을 찾아내어 이미지 분석을 수행하는 것이다.
고도화된 CNN 딥러닝 기술은 일상생활과 다양한 분야에 사람의 능력을 대체하거나 보조하는 기술로 활용되고 있다. 예를 들어, 얼굴의 특징을 학습하여 스마트폰의 얼굴 인식 잠금, 사진 앱의 얼굴 태그, 보안 시스템의 얼굴 인식 등 기능을 구현할 수 있다. 더불어 의료 영상에서 병변이나 종양 등의 특징을 학습하고 검출하여 의사의 진단을 돕거나, 암이나 심장병 등의 질병을 조기에 발견하는 기능도 구현할 수 있다. 이 외에도 객체탐지(object detection)를 통해 물류창고나 공장에서 물품을 분류할 수 있으며, 자율주행 자동차 기술에서 사물을 탐지하고, 드론 영상에 사람을 탐지하여 인명을 구조하는 등 사람들이 살아가는 여러 환경에서 CNN 딥러닝이 사용되고 있다.
CNN 딥러닝 기술들은 공간정보 및 조경·환경 분야에서도 활발하게 활용되고 있다. 위성영상에서 대규모 도시환경의 토지 피복 변화를 찾아내고(Zhang et al., 2019), 건물을 탐지(이대건 등, 2018)하는 등 이미 공간정보 분야에서는 공간정보와 인공지능의 합성어인 ‘GeoAI’로 개념화되어 딥러닝 기술이 사용되고 있다(VoPham et al., 2018). 구글 스트리트 뷰(Google Street View, GSV), 로드뷰 등의 데이터를 활용한 CNN 딥러닝 연구도 나타난다. Li et al.(2015)의 연구에서는 GSV의 CNN 딥러닝을 통해 도시의 녹시율(green view index, GVI)을 도출했다. 연구결과를 통해 도시 내 어떤 지역이 녹지 캐노피가 부족한지 손쉽게 파악할 수 있다. 박근덕과 이수기(2018)의 연구에서도 가로 보행 만족도 예측을 위해 GSV 사진을 딥러닝했다. 소셜미디어에 업로드된 다량의 사진을 대상으로 CNN 딥러닝을 진행한 연구도 나타난다. 강영옥 등(2021)의 연구에서는 SNS 사진을 통해 방문객과 거주자의 관광 활동 특성을 분석하여 관광객들의 활동 유형을 분석하고 마케팅적으로 활용하는가 하면, 이주경과 손용훈(2022)의 연구에서는 도시공원의 특성 평가를 위해 소셜미디어 사진을 활용해 자연성, 매력성, 이용자들의 활동 범주로 분류할 수 있는 CNN 딥러닝 모델을 개발했다. 윤혜진과 이현수(2022)의 연구에서는 핀터레스트(Pinterest)에서 사진을 수집하여 한옥카페의 전통성을 구별하는 CNN 딥러닝 모델 개발과 CNN 딥러닝 모델이 어떤 특징점을 기준으로 전통성을 구분하는지 시각화해 주는 Grad-CAM을 활용하여 전통적인 한옥카페 디자인 가이드라인을 제시했다.
위와 같은 연구의 분석 과정은 사람이나 전문가들이 직접 분석하기엔 접근하기 힘든 엄청난 규모와 양이며, 분석 시간도 오래 걸린다. 하지만 위 연구 모두 인간의 신경세포인 뉴런을 흉내 내는 인공신경망을 딥러닝하여 컴퓨터에 입력시켜 대량의 작업을 처리함으로써 인간이 만들어 내기엔 많은 양의 데이터 분석 결과를 빠른 시간에 일정한 정확도로 도출하여 효율적인 연구를 진행했다. 이러한 CNN 딥러닝의 장점을 활용하여 본 연구에서는 소셜미디어에 산재된 대량의 사진 테이터를 대상으로 CNN 딥러닝을 활용해 경관 이미지를 분석하고자 한다.
기존 경관 이미지를 분석하기 위한 방법에는 대표적으로 임승빈과 신지훈(1996)이 제안한 경관 형용사를 활용한 경관영향평가 방법과, 주신하와 임승빈(2003)이 제안한 경관 형용사를 활용한 도시경관분석 방법 등이 있다. 이들 방법은 설문조사나 집단 인터뷰 등의 방식으로 경관에 대한 인식을 조사하고 분석한다. 그러나 설문조사나 인터뷰 방법은 인원 모집에 필요한 비용과 시간이 많이 드는 단점이 존재한다.
기존의 단점을 보완하기 위해 CNN 딥러닝을 활용하여 경관 선호도를 반영한 사진을 학습한다면, 대량의 사진 데이터를 경관 분석할 수 있다. Zhang et al.(2018)의 연구는 경관 형용사가 반영된 사진을 CNN 딥러닝에 학습시킨 대표적인 사례이다. 연구에서는 사람들의 장소 및 경관 인식을 분석하기 위해 ‘safe’, ‘lively’, ‘beautiful’, ‘wealthy’, ‘depressing’, ‘boring’ 6개의 형용사 지표를 선정했다. 이후 온라인으로 장소 경관에 대해 평가가 가능한 웹사이트를 구축하고 81,630명의 온라인 참가자에게 GSV 사진을 보여주어 쌍체비교를 통한 형용사 평가를 진행했다. 평가가 완료된 데이터 셋을 CNN 딥러닝에 학습시켜 2개 도시의 거리를 6가지 형용사 인식으로 지도에 매핑(mapping)했다. 이후 거리 사진들을 객체 탐지를 활용해 경관 요소를 분석하여 인식에 대한 원인을 규명했다.
김유진과 강영은(2021)의 연구에서는 경관 평가 시 CNN 딥러닝 적용의 가능성과 타당성을 검토했다. 그 결과 CNN 딥러닝의 자동화 분류, 시계열적 변화의 분석, 대용량 데이터의 빠른 분류를 장점으로 제시했으며, 경관 사진을 많이 활용하는 점에서 CNN 딥러닝을 활용한 경관 분석 및 평가 분야의 발전 가능성이 높다고 평가했다.
선행연구의 사례를 보았을 때 CNN 딥러닝은 경관을 분석하거나 평가하는 데 있어 충분히 활용 가능한 방법이다. 따라서 본 연구에서는 기존 경관 이미지 평가 시 평가자에게 경관 사진을 보여주고 이에 대한 의견을 직접 평가자에게 묻는 방법을 CNN 딥러닝을 활용해 컴퓨터가 자동으로 사진을 분류할 수 있도록 하고자 한다.
3. 연구방법
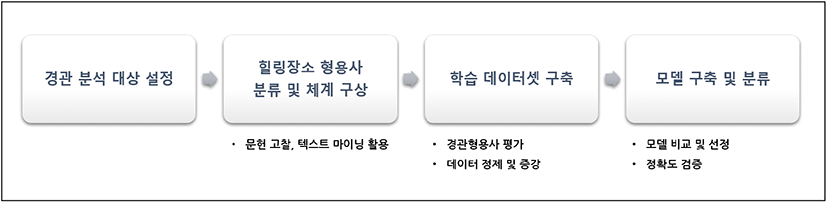
본 연구에서는 소셜미디어에 산재되어 있는 사진 데이터를 통해 장소의 경관을 분석하기 위해 CNN 딥러닝을 활용했다. 이를 위해 다음과 같은 일련의 방법들을 거친다. 첫 번째로 경관 분석을 위한 대상을 설정한다. 본 연구에서는 연구의 대상으로 힐링장소를 설정했다. 두 번째로 다량의 사진들을 어떤 범주로 분류할 것인지 분류 체계 구상과 설정이 필요하다. 본 연구에서는 힐링장소의 경관 형용사 이미지를 분류하고자 넷마이너(NetMiner 4.0)를 활용한 블로그 게시물 텍스트마이닝과 선행연구 고찰을 통해 힐링과 관련된 7가지 경관 형용사를 도출하여 범주로 선정했다. 또한 광고, 제품 사진 등 본 연구의 대상인 힐링장소와 관련 없는 사진을 분류하기 위해 ‘기타’와 ‘실내’ 2개의 범주를 추가하여 총 9개의 범주를 설정했다. 세 번째로 CNN 딥러닝의 학습을 위한 학습 데이터 셋 구축이 필요하다. 경관 형용사를 분석하기 위한 데이터 셋 구축을 위해 20대 남녀 50명의 평가자를 모집하여 포털사이트에서 ‘힐링’, ‘힐링장소’, ‘힐링풍경’으로 검색되는 사진에서 7가지 형용사별로 3장씩 수집하도록 했다. 광고, 제품 사진, 실내 사진 등을 분류하기 위한 ‘기타’와 ‘실내’ 2가지 범주의 데이터 셋은 연구자가 포털사이트에서 검색하여 수집했다. 이후 수집된 학습 데이터 셋을 정제하고, 부족한 데이터를 증강했다. 마지막으로 수집된 학습 데이터 셋을 통해 모델을 구축했다. 모델 구축의 시간 단축과 높은 정확도를 위해 기존 학습되어 배포된 CNN 딥러닝 모델에 전이학습(transfer learning)을 진행했다. 전이학습이란 이미 학습된 CNN 딥러닝 모델에 새로운 목적을 위한 학습을 진행함으로써 학습 시간과 학습 데이터 부족으로 인한 성능 저하를 줄이는 방법이다(정소영과 정민교, 2019). 기존 여러 가지 CNN 딥러닝 모델 중 본 연구에서 수집된 사진을 학습하는 데 학습 소요 시간이 적게 들며, 정확도가 높은 모델을 비교하기 위해 10가지 모델을 비교했다. 그 결과 최종적으로 VGG16을 본 연구에서 전이학습으로 사용될 모델로 선정했다. 이후 VGG16 모델의 정확도를 높이기 위해 학습 횟수를 증가시켜 심층적으로 학습했으며, 테스트 데이터 셋을 통해 모델의 정확도와 성능을 검증했다. 구축된 힐링장소 경관 분석 CNN 딥러닝 모델을 활용해 본 연구에서 분석하고자 하는 힐링장소의 사진 15,097장을 수집하여 형용사별로 사진을 분류했다. 일련의 연구 과정은 다음과 같다(그림 2 참조).
본 연구에서 사용된 개발 환경은 다음과 같다. 우선 사진 데이터 수집은 Python 3.9의 Selenium 라이브러리를 통해 사진을 수집했다. 다음으로 CNN 딥러닝은 구글 코랩(Google Colab)의 스탠다드 버전을 이용했다. 구글 코랩은 클라우드 기반의 개발 환경으로, 무료 버전과 유료 버전이 있다. 무료 버전은 메모리나 그래픽 처리 장치(graphics processing unit, GPU) 자원의 한도, 유효 제한 시간, 가상 머신(virtual machine, VM)의 최대 수명 등이 유료 버전보다 제한적이며, 그래픽 처리 성능도 낮다. 일정 세션 시간이 지나면 작업하던 데이터가 사라진다는 단점도 있다. 그러나 PC에 별도로 개발 환경을 설치하거나 설정할 필요가 없으며, 딥러닝을 위한 고성능의 그래픽 처리 장치를 무료로 사용할 수 있다는 장점이 있다. 이러한 이유로 구글 코랩은 다양한 분야의 머신러닝, 딥러닝 연구에서 활용되고 있다(오병우, 2022; 김서영 등, 2023). 사진 데이터 수집을 위해 사용된 PC의 사양은 AMD Ryzen R9 5950x 3.4GHz, Nvidia GTX 1080 8G, RAM 48GB이며, 딥러닝을 위해 사용된 구글 코랩 스탠다드 버전의 중앙 처리 장치(central processing unit, CPU)와 그래픽 처리 장치 사양은 Intel Xeon CPU 2.20GHz*2, Nvidia Tesla T4 8G이다.
본 연구에서는 경관 분석 단계에서 딥러닝 모델을 검증하기 위해 힐링장소를 분석 대상으로 설정했다. 선행연구에서는 힐링장소를 어떤 상처나 후유증을 치유하는 목적보다는 사회에서 받은 스트레스의 해소, 분위기 전환, 휴식, 여유를 느끼는 공간 환경으로 정의하고 있다(Olds, 2001; 고정훈, 2015; 오지영과 박혜경, 2019). 본 연구에서는 힐링장소의 경관을 분석하기 위해 공간적 범위를 건물 내부나 특정 물체가 아닌, 옥외 환경으로 한정한다.
학습 사진 수집에 앞서 힐링과 관련되는 경관 형용사를 도출했다. 이를 위해 2012년부터 2021년까지 ‘힐링’으로 검색되는 네이버 블로그 게시글 88,155건을 수집했다. 이후 넷마이너를 활용한 텍스트마이닝을 통해 총 295개의 형용사 키워드를 도출했다. 이후 다른 키워드들과 연관성이 높으며 중요한 위치에 있음을 나타내주는 중심성을 분석했다. 중심성 분석 결과 최대 중심성은 0.156463, 최소 중심성 0으로 나타났으며, 평균 중심성은 0.009927058로 약 0.01로 나타났다. 도출된 형용사 중 중심성 평균값 이상의 형용사 24개를 도출했다(표 1 참조).
이후 도출된 24개의 형용사를 선행연구 고찰을 통해 유형화했다. 주신하와 임승빈(2003)의 연구에서는 경관 형용사의 유형을 ‘자연성’, ‘개방감’, ‘복잡성’, ‘신비감’, ‘위요감’, ‘안전성’, ‘응집성’, ‘친근성’, ‘가독성’, ‘정연성’, ‘심미성’, ‘물리적특성’, ‘기타’로 분류하고 있다. 이를 토대로 24개의 경관 형용사를 다음과 같이 분류했다(표 2 참조).
| 유형 | 개방감 | 정연성 | 심미성 | 위요감 | 자연성 | 복잡성 | 물리적특성 (온도) | 물리적특성 | 기타 |
|---|---|---|---|---|---|---|---|---|---|
| 경관 형용사 | 넓다, 답답 | 깨끗, 깔끔 | 좋다, 싫다, 아름답다, 예쁘다 | 포근 | 맑다, 상쾌 | 조용, 한적, 복잡 | 시원, 따뜻, 춥다 | 많다, 작다, 길다, 짧다 | 힘들다, 즐겁다, 맛있다 |
경관 형용사 유형 중 ‘개방감’, ‘정연성’, ‘심미성’, ‘위요감’, ‘자연성’, ‘복잡성’을 선정했으며 추가로 ‘기타’ 유형의 ‘즐겁다’를 선정했다. 경관 평가 및 사진 데이터 수집의 용이성을 위해 유형 내 해당하는 형용사들을 선택하여 최종적으로 ‘개방적인’, ‘깨끗한’, ‘아름다운’, ‘안락한’, ‘자연적인’, ‘조용한’, ‘즐거운’ 총 7가지의 형용사를 본 연구에서 활용할 힐링장소 경관 형용사로 선정했다.
학습 데이터 수집을 위한 평가자 모집에 앞서 네이버, 다음, 구글 3개의 포털사이트에서 ‘힐링’, ‘힐링장소’, ‘힐링풍경’ 3가지의 검색어로 2012년부터 2021년까지 1년 단위로 검색하여 총 90개의 이미지 검색 결과에 대한 웹사이트 링크를 수집했다. 이후 경관 형용사 평가를 위해 20-29세의 남녀 평가자 50인을 모집했다. 평가자들에게는 각자 무작위의 다른 링크를 부여하여 링크 내에서 7개의 형용사에 대한 사진을 형용사별로 3장씩 수집하게 했다. 평가자마다 포털사이트, 검색어, 기간이 다른 이미지 검색 결과 링크를 무작위로 부여한 이유는 평가자마다 중복되는 사진의 수집을 줄이고 보다 다양한 학습 데이터를 수집하기 위함이다. 추가로 양질의 학습 데이터 수집과 옥외 환경에서 촬영한 사진으로 한정하기 위해 50인의 평가자에게 다음과 같은 다섯 가지 조건을 제시했다.
첫 번째, 실내를 제외한 야외 풍경(경관) 사진 수집
두 번째, 물체나 특정 대상이 아닌 풍경(경관) 사진 수집
세 번째, 사람의 눈높이에서 촬영한 사진 수집
네 번째, 카메라 촬영에 의한 사진 수집
다섯 번째, 뉴스 로고, 브랜드 마크, 텍스트가 포함되지 않은 사진 수집
위 조건에 부합한 7개의 형용사에 해당하는 사진들이 표 3과 같이 평가자들에 의해 수집됐다. 평가자들에 의해 수집된 사진들을 살펴보자면 ‘개방적인’의 형용사는 주로 바다나, 산, 들판에서 찍은 사진이었으며 전방 시야에 방해되는 요소가 없거나 지평선이 보이는 사진이 수집됐다. ‘깨끗한’ 형용사는 바다나 호수가 맑아 반사되거나 눈이 쌓인 풍경 등의 사진이 주로 수집됐다. ‘아름다운’ 형용사는 노을이 지는 풍경과 형형색색의 단풍, 꽃이 있는 사진이 수집됐다. ‘안락한’ 형용사의 경우 주로 숲속이나 산책로 등 주변이 위요된 환경 사진이 수집되었으며, 농촌 마을의 경관 사진 또한 수집됐다. ‘자연적인’의 경우 하천이나 농경지, 목초지 등 자연의 경관 사진이 주로 수집됐다. ‘조용한’ 형용사는 마을 길, 정자, 쉼터, 안개 낀 숲길 등의 경관 사진이 수집되었고, 마지막으로 ‘즐거운’의 경우 주로 사람들이 야외에서 활동하는 사진이나 폭포, 계곡 등의 사진이 수집됐다.

위 7가지 형용사와 별개로 연구결과에서 광고 사진이나 실내 사진, 인물 위주의 사진을 걸러내기 위해 ‘기타’와 ‘실내’ 범주를 추가했다. ‘기타’와 ‘실내’의 경우 연구자가 직접 사진을 수집했다. ‘기타’ 범주는 인터넷 사이트 쇼핑몰에서 판매되는 힐링 관련 상품과 홍보 게시글, 전단지 사진, 뉴스 기사, 인물 위주의 사진 등을 포함했고 ‘실내’의 경우 카페, 도서관, 펜션 내부 사진 등을 포함했다.
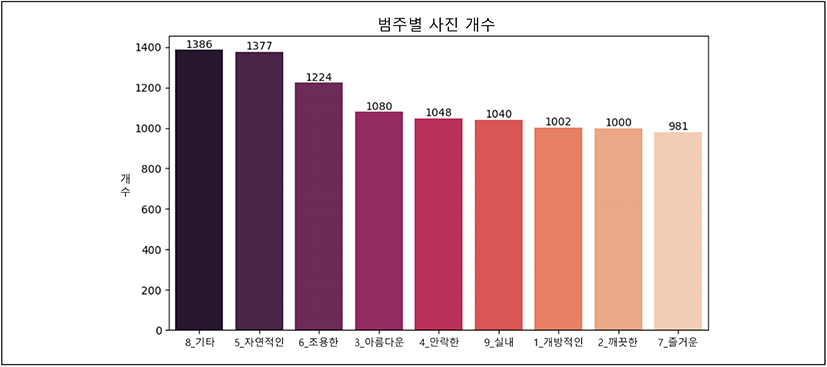
이후 수집된 9가지 범주마다 중복되는 사진을 제거했다. 사진이 중복되어 학습될 때 해당 경관 이미지에 대한 학습 가중치가 높게 되는 것을 방지하기 위함이다. 각 범주 내에서 중복된 사진 중 데이터의 크기가 가장 큰 것을 제외하고 나머지를 제거했다. 최종적으로 학습에 사용된 사진은 ‘개방적인’ 143장, ‘깨끗한’ 144장, ‘아름다운’ 143장, ‘안락한’ 144장, ‘자연적인’ 143장, ‘조용한’ 144장, ‘즐거운’ 143장이었으며 ‘기타’ 342장, ‘실내’ 174장을 추가하여 총 1,377장이다.
수집된 학습 사진을 통해 분류할 수 있는 모델을 제작했다. CNN 딥러닝 학습에는 모델의 정확도를 위해 각 범주당 최소 1,000건 이상의 학습 데이터를 권장하고 있다(Zhou et al., 2022). 본 연구에서 50명의 평가자를 통해 수집된 사진은 7개 형용사 범주별로 143장 혹은 144장이었으며, 기타 342장, 실내 174장으로 학습을 위한 최소 데이터 수에 못 미치는 수준이다. 학습을 위한 데이터 수를 보완하기 위해 데이터 증강(data augmentation) 과정을 거쳤다. 데이터 증강이란 작은 규모의 학습 데이터 셋을 좌우대칭(mirror), 임의적 자르기(random crop), 회전(rotate), 색 변환(pixel level transform) 등 편집을 통해 데이터의 양을 늘려 모델의 학습 성능을 향상시키는 기술이다(Ni et al., 2021). 본 연구에서는 좌우대칭, 임의적 자르기, 색 변환을 통해 사진 데이터 셋을 증강했다. 연구에서 학습을 위해 사용된 사진 데이터의 개수는 10,138개이며, 범주별 사진 개수는 다음과 같다(그림 3 참조).
데이터 증강 과정을 거친 후 힐링장소 경관을 분석하기 위한 CNN 딥러닝 모델을 제작했다. CNN 딥러닝에는 아키텍처(Architecture)라는 다양한 모델이 있는데 모델별로 주요 특징점이 다르다. 예컨대 CNN의 시초라고 할 수 있는 LeNet(LeCun et al., 1989)은 우편 서비스의 우편번호나 숫자를 인식하기 위해 만들어졌으며, 정확도를 대폭 향상하여 ILSVRC 2012에서 우승한 AlexNet(Krizhevsky et al., 2017)은 사물이나 동물들을 분류하는 데 최적화되어있다. 본 연구에서는 수집된 형용사가 반영된 사진을 우수하게 학습시키는 모델을 비교 후 선정했다. 이를 위해 동일한 학습 데이터를 기준으로 다양한 모델을 사전학습 시켜본 후 모델별 학습 소요 시간과 모델 정확도를 도출했다. 이후 학습 소요 시간은 적게 걸리며 정확도가 높은 모델을 선정했다.
본 연구에서는 제작된 CNN 모델의 성능을 평가하기 위해 혼동행렬(confusion matrix)과 정확도(accuracy), 민감도(sensitivity, recall), 정밀도(precision), F1 score를 사용했다. 혼동행렬이란 모델이 예측한 분류(perdiction class)와 데이터의 실제 분류(actual class)를 비교하여 정확하게 분류된 데이터의 수를 표현한 행렬이다. 혼동행렬을 통해 정확도, 민감도, 정밀도, F1 score를 계산할 수 있다. 정확도란 전체 데이터 중에서 올바르게 분류된 데이터의 비율로써 정확도가 높을수록 모델의 성능이 좋다고 할 수 있다. 민감도는 참(positive)인 데이터 중에서 올바르게 참으로 예측된 데이터의 비율로서 민감도가 높을수록 모델이 참인 데이터를 잘 찾아낸다고 할 수 있다. 정밀도는 참으로 예측된 데이터 중에서 실제로 참인 데이터의 비율로서 정밀도가 높을수록 모델이 참인 데이터를 잘 구분한다고 할 수 있다. F1 score는 정밀도와 민감도의 조화평균으로, 데이터의 라벨이 불균형할 때 모델의 성능을 평가하는 데 유용하다. F1 score가 높을수록 모델의 성능이 좋다고 할 수 있다.
위 5가지의 평가 지표들은 0-1 사이의 값을 가지고 있다. 이주경과 손용훈(2022)의 연구에서는 CNN 딥러닝 모델을 평가할 때 정밀도와 민감도가 0.8 이상이면 높은 성능으로 판단했으며, 두 지표의 차이가 작을수록 모델 성능에 문제가 없다고 판단했다. 또한, F1 score가 0.9 이상이면 우수한 분류 모델로 보았다.
제작된 모델을 활용하여 힐링장소의 경관 이미지를 분류하기 위해 포털사이트 다음(https://www.daum.net)에서 힐링장소 사진을 수집했다. 사진 수집 기간은 2012년부터 2021년까지이며 검색 기간의 단위는 1년 단위로 검색했다. ‘힐링’으로 검색되는 사진 8,046장, ‘힐링풍경’으로 검색되는 사진 7,051장, 총 15,097장을 수집했다(표 4 참조).
| 검색어 | 2012년 | 2013년 | 2014년 | 2015년 | 2016년 | 2017년 | 2018년 | 2019년 | 2020년 | 2021년 | 합계 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 힐링 | 743 | 844 | 954 | 904 | 839 | 841 | 805 | 661 | 772 | 683 | 8,046 |
| 힐링풍경 | 1,066 | 503 | 433 | 590 | 657 | 667 | 832 | 839 | 701 | 763 | 7,051 |
4. 힐링장소 경관 이미지 분석
모델 제작에 앞서 전이학습을 위해 기존 배포된 CNN 딥러닝 모델들의 학습 능력을 비교 및 선정했다. 데이터 증강 과정을 거친 9개 범주에 대한 10,138개 사진을 기존 배포된 10개의 CNN 딥러닝 모델에 전이학습을 진행했다. 모델별 정확도와 소요 시간 테스트를 위해 총사진 개수의 10%를 무작위로 배치하여 테스트를 진행했다. 각 모델은 학습 횟수인 에포크(epoch)를 모두 7회로 설정하여 동일한 조건에서 학습시켰으며 결과는 다음과 같다(표 5 참조).
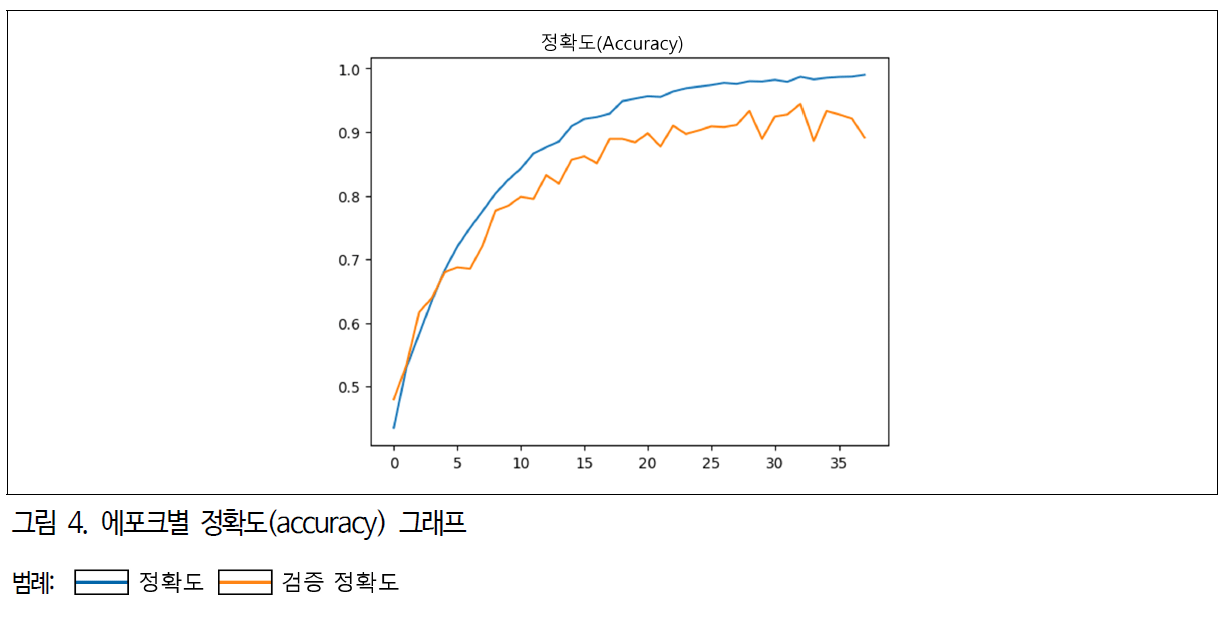
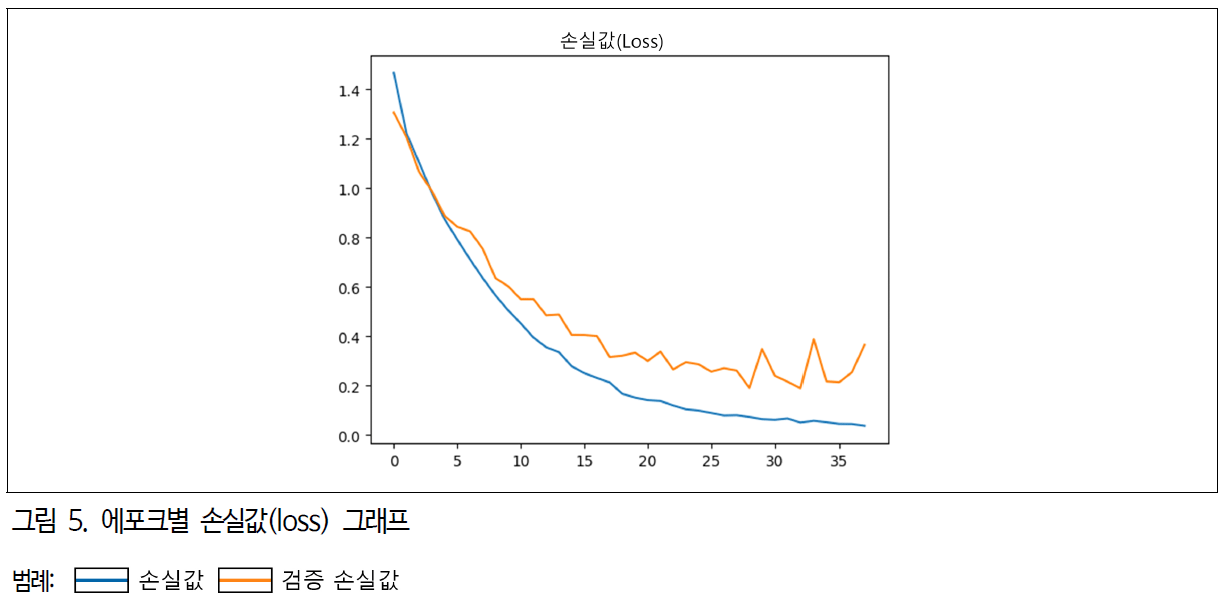
10개의 CNN 딥러닝 모델에서 VGG16 모델이 가장 소요 시간이 적게 걸리고 정확도가 높게 나타나 VGG16 모델을 본 연구의 분류모델로 선정했다. 이후 VGG16 모델의 정확도를 높이기 위해 에포크 횟수를 늘려 심층 학습을 진행했다. 진행된 에포크 횟수는 50회로 최종 정확도는 0.9900(그림 4 참조)이고 손실값은 0.0377(그림 5 참조)로 나타났다.
VGG16을 기반으로 전이학습된 분류모델을 평가하기 위해 학습 데이터의 10%를 테스트 데이터로 배치하여 모델을 평가했다. 우선, 분류된 9개의 각 범주의 결과를 혼동행렬로 시각화했다(그림 6 참조). ‘실내’의 범주가 정확도 1.00으로 가장 높게 나타났으며, ‘개방적인’의 범주가 0.63으로 가장 낮게 나타났다. 이는 모델이 ‘실내’ 범주를 정확하게 분류하는 능력이 가장 높고, ‘개방적인’ 범주를 정확하게 분류하는 능력이 가장 낮음을 의미한다. 유의미한 가중평균 정확도의 값인 0.8 이하인 범주는 ‘개방적인’(0.63), ‘안락한’(0.69)이다. ‘개방적인’과 ‘안락한’의 범주에서 가중
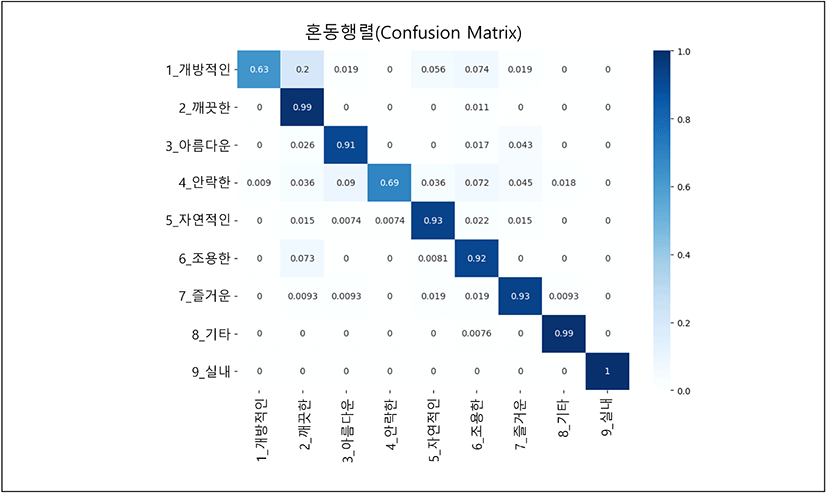
평균의 정확도가 0.8보다 낮게 나타났으나 모델의 평균 정확도가 0.91로 나타나 모델을 활용하기로 했다.
다음으로 자세한 모델의 성능 평가를 위해 정밀도, 재현율, F1 score를 산출했다(표 6 참조). 모델 전체 정밀도의 가중평균은 0.91로 나타났고, 재현율의 가중평균은 0.89로 나타났다. 또한, F1 score의 가중평균이 0.89로 나타나 해당 모델은 정확도나 구조에 대한 문제가 없음을 확인했다.
제작된 CNN 딥러닝 모델을 활용하여 힐링장소의 경관을 분석하기 위해 포털사이트 다음에서 ‘힐링’과 ‘힐링풍경’으로 검색하여 수집한 15,097장의 사진을 분류했다(표 7 참조).
힐링장소 사진 15,097장 중 ‘기타’와 ‘실내’ 범주를 제외한 7가지 형용사 분류 결과는 ‘조용한’ 2,093장(22%), ‘개방적인’ 2,005장(21%), ‘즐거운’ 1,727장(19%), ‘안락한’ 1,436장(15%), ‘깨끗한’ 803장(9%), ‘자연적인’ 754장(8%), ‘아름다운’ 513장(5%) 순으로 나타났다. ‘조용한’과 ‘개방적인’, ‘즐거운’의 사진이 61%로 나타나 사람들이 생각하는 힐링장소의 이미지는 조용하거나, 개방적이거나, 즐거운 환경으로 인식한다고 볼 수 있다.
앞선 ‘3.3 경관 형용사를 반영한 학습 사진 수집’에서 평가자들이 수집한 사진과 형용사를 대조를 해보자면 마을 길, 정자, 쉼터, 안개 낀 숲길과 같은 조용한 장소의 사진, 바다나 산, 들판, 전방 시야에 방해되는 요소가 없거나 지평선이 보이는 개방적인 장소의 사진, 사람들의 활동이 많이 일어나고 폭포나 계곡 등 역동적인 개체가 있는 즐거운 장소의 사진을 힐링장소로 인식한다고 볼 수 있다.
5. 결론
본 연구는 소셜미디어 사진 데이터를 통해 특정 장소의 경관 분석하고자 CNN 딥러닝을 활용했으며, 연구의 대상으로 힐링장소를 설정했다. 학습 데이터 수집을 위해 ‘힐링’과 관련된 7가지 경관 형용사를 도출하고 이후 50인의 평가자를 모집하여 7가지 경관 형용사에 부합하는 ‘힐링장소’의 사진을 각 형용사별로 3장씩 수집하도록 했다. 추가로 광고 사진, 실내 사진, 인물 위주의 사진을 걸러내기 위한 ‘기타’와 ‘실내’에 해당하는 사진을 연구자가 직접 수집하여 총 9가지 범주에 대한 학습 데이터를 CNN 딥러닝에 학습시켰다. 학습된 CNN 딥러닝 모델을 활용하여 총 15,097장의 힐링장소 사진에 대한 경관 이미지를 분류했다. 그 결과 ‘조용한’, ‘개방적인’, ‘즐거운’에 해당하는 사진이 각각 22%, 21%, 19%로 분류되었다. 연구를 통해 사람들은 힐링장소의 이미지를 ‘조용한’, ‘개방적인’, ‘즐거운’으로 인식하는 것을 알 수 있었다.
연구를 통해 CNN 딥러닝을 통한 경관 이미지 분석 방법은 경관 이미지 분석 결과를 도출할 수 있는 방법임을 알 수 있었다. CNN 딥러닝을 통한 경관 이미지 분석 방법이 시사하는 바는 다음과 같다. 첫 번째, 15,097장의 사진을 일정한 정확도로 하여 경관 형용사를 분석했다. 평가집단을 통해 15,097장의 사진을 분석한다면 분석 과정에
서 오류나 정확도의 문제가 발생할 수 있는 점에서 CNN 딥러닝을 통한 경관 이미지 분석 방법은 장점이 있다. 두 번째로 학습 데이터의 구축을 위한 평가집단 모집 외에 대량의 사진 데이터를 분석하는 데 있어 평가집단을 모집하지 않았다. 15,097장의 경관 이미지 평가를 위한 평가집단의 모집이 필요하지 않았으며, 이는 기존 경관 이미지 분석 방법론에 비해 시간과 비용을 줄일 수 있다. 학습 데이터가 구축이 되어있는 경우에는 학습 데이터 구축을 위한 평가집단 또한 모집하지 않아도 되는 장점이 있다. 세 번째로 힐링장소에 대한 이미지를 표준화할 수 있었다. 주관적인 성향이 강한 힐링장소에 대해 15,097장의 사진을 분류하여 힐링장소를 어떤 이미지로 가장 많이 느끼는지 정량화할 수 있었다. 본 연구에서는 7가지 경관 형용사에 대해서만 분석을 진행했지만, 더 많은 경관 형용사 학습데이터가 구축된다면 힐링장소의 경관에 대해서 심층적인 분석이 가능할 뿐만 아니라 다양한 장소, 경관, 대상에 대해 경관분석을 진행할 수 있을 것이다.
본 연구의 한계점으로는 경관 분석을 위한 학습 데이터의 부족을 지적할 수 있겠다. 공공이나 학술 차원에서 CNN 딥러닝을 위한 학습 데이터를 개방하는 사례도 많이 늘고 있지만, 대부분의 데이터 셋이 사물, 인물, 동물, 행동 등에 그치고 있다(AIHub, ETRI AI 나눔). 기존 CNN 딥러닝은 글씨나 사물을 분류하는 데 주로 쓰였기 때문에 대부분의 학습 데이터 셋이 글씨, 사람, 자동차, 동물 등 명확한 객체에 대해서 구축되어 있다. 경관과 관련한 학습 데이터 셋도 건물, 하늘, 도로 등의 사진 데이터 셋이 구축되어 있을 뿐이다(Zhang et al., 2018; Chen et al., 2020). 따라서 경관을 분석하기 위해서는 다양한 경관 형용사를 반영한 사진 데이터 셋의 구축이 필요하다. 본 연구에서는 형용사 이미지가 반영된 사진을 수집했으나, 평가자의 수가 50명이었다. Zhang et al.(2018)의 연구에서 81,630명에게 형용사를 평가하여 데이터 셋을 구축한 것과 비교하면 그 수는 매우 적다고 볼 수 있다. 따라서 딥러닝을 활용한 경관 분석을 위해 형용사가 평가된 사진의 학습 데이터 셋 구축을 제안한다.
향후 연구를 위한 제언은 다음과 같다. 첫 번째, 본 연구에서는 도출된 결과에 대해 상호 관계를 분석하지 않았다. 예컨대 ‘조용한’과 ‘즐거운’의 경우 의미가 서로 모순되는 형용사로서 사람들이 힐링장소를 조용하면서 즐거운 경관을 선호하는 것인지, 혹은 조용한 경관과 즐거운 경관이 별개로 선호되는 것인지 알 수 없었다. 따라서 분석 결과에 대한 교차 분석이 이루어져야 할 것이다. 두 번째, 세부적인 경관을 분석하기 위해서는 경관 형용사 외에도 경관 구성요소, 행태, 사람들의 인식 등 다양한 요소들이 분석되어야 한다. 구체적인 장소의 경관 분석을 위해 사람들이 작성한 텍스트를 함께 분석하거나, 행태를 파악하거나, 분류된 이미지에 대한 상관분석이 필요하다. 더불어 세부적인 분석을 위해 산, 공원, 바다, 해변, 숲 등 장소적 요소, 봄, 여름, 가을, 겨울과 같은 계절적 요소, 낮과 밤과 같은 시간적 요소 등 다양한 경관적 요소들을 포함하여 사진을 구체적으로 분류할 필요성이 있다. 예를 들어 특정 장소의 경관 이미지에 대해 장소적 유형, 계절적 유형, 시간적 유형, 형용사를 분류할 수 있는 CNN 딥러닝 모델을 병렬적 구조로 순서대로 활용한다면 경관에 대해 보다 구체적인 분류와 분석 결과를 도출할 수 있을 것으로 사료된다. 병렬적 구조란 여러 요소에 대한 CNN 모델을 순차적으로 사용하는 것을 뜻한다. 장소적 유형인 ‘산’에서 계절적, 시간적 유형인 ‘여름’, ‘낮’에 찍은 사진이 많이 도출되어 사람들이 힐링으로 인식하는지, ‘가을’, ‘낮’에 찍은 사진이 많이 도출되어 사람들이 힐링으로 인식하는지 구체적 분류가 가능할 것이다.
향후 CNN 딥러닝을 활용한 경관 분석 방법이 구축되고, 조경 학문에서 활용할 수 있는 여러 방면의 다양한 사진 빅데이터가 구축된다면 조경계획 및 설계단계에서도 보조도구의 역할, 더 나아가 하나의 분석 방법 및 설계 방법으로 활용할 수 있을 것으로 기대한다.