




1. 서론
최근 급속히 발달하는 IT 기술과 데이터의 범람으로 인해 생활 모든 부분의 패러다임이 전환되고 있다. 이에 따라 인공지능, 빅데이터, 사물인터넷, 메타버스 등 다양한 기술적 변화를 마주하고 있다. 이러한 기술의 발전은 학술영역에도 영향을 미치고 있다. 특히, 다양한 학문의 교류와 연계를 통한 융합연구와 데이터 기반의 연구 방법이 다양하게 활용되고 있다.
인간과 자연의 조화를 통해 삶을 영위하는 쾌적하고 아름다운 환경을 조성하는 데 목적이 있는 조경학에서도 기존의 연구주제나 연구 방법의 변화가 나타나고 있다. 연구주제와 방법의 변화를 살펴보면 2010년 이후로 온라인 텍스트 데이터를 활용하여 의미를 찾아내는 텍스트마이닝 기법이 많이 활용되고 있다. 이러한 텍스트마이닝 기법은 기존의 연구 방법에 비해 시간과 비용을 절감하면서 연구의 효율성을 높여주는 장점을 가지고 있다(Woo, 2020). 그러나 요즘 소셜 미디어는 텍스트 위주의 정보보다 이미지를 통해 자신의 경험 또는 기분이나 느낌, 생각 등을 표현하는 것이 주를 이루고 있다(Huang and Lee, 2021). 이에 따라 빅데이터를 활용한 연구도 텍스트데이터를 통한 연구에서 이미지데이터를 분석하고 활용하는 연구로 전환되어야 할 필요성이 있다. 이처럼 이미지데이터를 기반으로 분석하는 머신러닝을 활용한 연구 방법이 활발하게 사용되고 있다. 특히, 머신러닝 기법의 경우 관련 학과 전공자뿐만 아니라 경제, 교통, 농업, 보건의료, 산림, 산업, 정보통신, 환경 등 다양한 분야에서 연구가 진행되고 있다. 하지만 조경학 분야에서 머신러닝을 활용한 연구는 미진한 실정이다. 따라서, 조경학 분야의 연구에서도 기술 발전에 따른 연구 방법을 활용해 볼 필요가 있다고 생각한다.
다양한 조경학의 연구 분야 중 경관은 단순히 보고 즐기는 경치의 차원을 넘어 인간의 생존을 지원해 주는 생태적 속성을 지닐 뿐만 아니라, 경관을 통하여 삶의 의미와 본질을 느끼도록 하는 상징적·철학적 속성을 지니고 있다(Im, 1991). 이처럼 인간에게 경관이란, 일상적 가치와 비일상적 가치 양쪽 모두를 지닌다(Shinohara, 2010). 이와 같은 중요성에 따라 경관의 선호를 평가하고 예측하는 연구가 지속적으로 진행되고 있다. 그러나 기존의 연구 방법은 연구자가 직접 촬영한 경관 이미지를 설문조사를 통해 경관을 관찰하는 사람들의 주관적인 개인적 선호를 가능한 객관적으로 측정하여 경관미를 평가하고 예측할 수 있다는 효용성이 있지만 예측 연구를 진행하는 데 시간과 비용이 많이 들고, 예측의 정확도를 높이기 위해 많은 표본 수를 얻어야 하는 어려움을 한계로 가진다. 반면에 머신러닝 기법은 빅데이터의 시대에 공개된 수많은 이미지 데이터를 분석에 적합한 데이터로 정제하여 학습시킨다면, 기존의 경관 연구 방법이 가지는 한계점과 현재 많이 활용되고 있는 텍스트마이닝 분석이 가지는 과거 현상에 대한 추세를 통한 미래 예측의 어려움이 있다는 한계점을 보완하고 정확도 높은 예측모델의 도출이 가능할 것으로 판단된다(Kim, 2017).
이에 따라 본 연구에서는 머신러닝을 활용하여 경관 지각반응 예측모델 구축하고, 경관 선호 평가의 가능성을 알아보고자 하였다. 인공지능을 활용한 기초단계의 연구지만 경관 선호 예측에 있어 효용적인 방법론의 기초연구로서의 가치를 확인하고 경관 평가 연구영역의 확대에 기여하는 것을 본 연구의 의의로 가진다.
2. 연구 방법
본 연구는 최근 신재생에너지 사업으로 주목받는 풍력발전시설의 경관을 연구 대상으로 선정했다. 이는 경관 지각반응 예측모델 개발 가능성에 대한 기초연구를 진행함에 있어 데이터의 수집이 용이하고 시설과 경관의 구분이 뚜렷하여 예측 모델의 평가 기준을 적용하고 학습과 예측평가를 통한 연구 진행에 적합하다고 판단했다. 이에 풍력발전에 관련된 이미지 데이터를 수집하여 연구데이터를 구축한다. 이를 위한 연구의 범위는 다음과 같다. 인터넷 검색엔진 네이버, 다음, 구글과 이미지 기반 소셜네트워크서비스인 인스타그램의 검색어 ‘풍력발전’으로 수집되는 이미지를 기초자료로 한정하여 연구를 진행하였다.
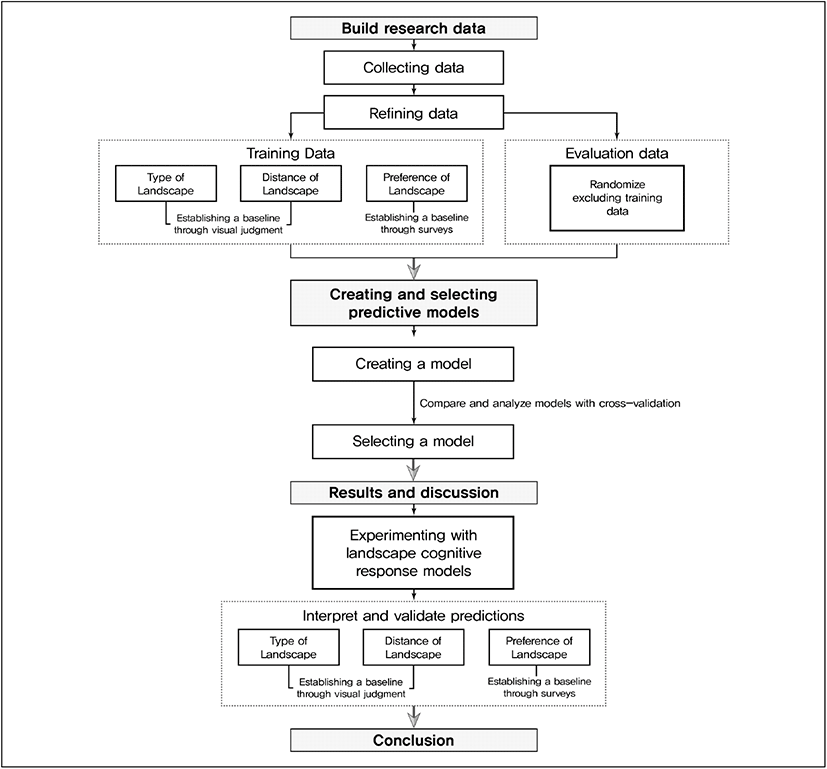
본 연구의 머신러닝을 활용한 경관 지각반응 예측모델 개발 가능성 기초연구를 위해 먼저 연구 데이터 구축과정을 진행하였다. 이에 따라 예측모델 구성에 필요한 풍력발전시설 경관에 관한 자료수집을 진행했다. 이후 수집한 데이터를 정제하고 학습데이터와 평가데이터로 구분하였으며, 학습데이터는 추가로 예측모델의 평가 기준 학습을 위해 전처리를 진행하였다. 평가 기준 3가지 중 경관의 선호 기준은 관련 전공자 30명의 설문지를 통해 설정하였다. 이와 같은 과정을 통해 연구 데이터 구축을 진행하였다. 다음은 예측모델의 생성 및 선정 과정으로 지도학습에 사용되는 다양한 분류 알고리즘을 활용하여 예측모델을 생성하고 성능평가를 통해 생성된 예측모델 중 본 연구에 적합한 예측모델을 선정하였다. 마지막으로 결과 및 고찰을 통해, 연구 과정을 통해 생성한 예측모델로 지각반응 평가를 수행하였다. 이에 따른 예측모델의 결과를 해석하고 평가데이터의 추가적인 검증과정을 거친다. 이러한 검증과정에서도 경관의 선호 기준은 관련 전공자 30명의 설문지를 통해 설정하였다. 이러한 과정을 통한 예측모델의 성능지표와 검증결과의 성능지표 비교분석을 진행하여 경관분석의 관점에서 머신러닝의 활용성을 알아보았다. 연구 과정의 흐름도는 Figure 1과 같다.
본 연구에 필요한 데이터는 풍력발전에 관련된 이미지 데이터로 한정하였다. 이미지 데이터의 수집 채널은 검색엔진 네이버, 다음, 구글 3개 사 이미지 검색과 이미지 기반 SNS 인스타그램의 해시태그 검색을 이용하였다.
머신러닝에 연구에 활용할 데이터이기 때문에 데이터의 양이 많은 것이 좋다고 판단되어 ‘풍력발전’ 검색 키워드와 ‘풍력발전’ 해시태그로 검색되는 모든 이미지를 수집하였다. 이를 위하여 파이선 주피터 노트북 환경에서 selenium 모듈과 beautifulsoup 모듈을 활용한 코드로 동적 페이지 웹 크롤링을 진행하였다. 데이터의 수집 결과는 Table 1과 같으며 수집된 데이터의 예시는 Figure 2와 같다.

본 연구를 진행하기 위하여 수집한 이미지 데이터 정제과정을 수행하였다. 연구에 적합한 이미지 데이터를 확보하기 위하여 인물, 음식, 광고, 접사 등 불용사진과, 2장 이상 수집된 중복사진, 풍력발전 시설 자체만 촬영하여 경관이 담기지 않은 사진을 제거했다. 또한, 사진의 크기가 너무 작아 경관과 풍력발전시설이 식별하기 어려운 사진도 제외하였다. 이를 통하여 본 연구에서 적합한 이미지 데이터 2,080장을 선정했다. 일차적으로 정제한 이미지 데이터 2,080장을 모두 활용하여 모델을 학습시키면 우수한 모델을 생성할 수 있으나, 학습데이터에 평가 기준을 부여하기 위한 전처리를 위해 데이터의 한정이 필요하다. 이에 따라 머신러닝에 활용되는 데이터분석 프로그램 오렌지의 ‘Data Sampler’ 기능을 활용하여 전체의 20%인 416장을 무작위 추출하였다. 이 중 학습에 사용하기 어려운 20장은 제외하고 총 396장의 이미지 데이터로 한정했다. 이후 머신러닝 지도학습 모델의 평가 기준을 설정했다. 경관 지각반응 예측모델은 풍력발전시설의 경관을 대상으로 3가지 평가 기준을 가지도록 구성했다. 본 연구에서 설정한 학습데이터의 평가 기준은 아래와 같고 평가 기준을 정리한 것은 Table 2와 같다.
* Source : Higuchi(1983); Yoshinobu(1994); Yoo(2000); Shinohara(2010); Hong(2010) to reorganize researchers.
첫 번째로 풍력발전시설 경관의 유형을 기준으로 선정하였다. 본 연구의 평가대상은 일반적인 풍력발전시설의 입지 유형과는 차이를 가지는 개념으로 시설의 입지만으로 판단하기보다 이미지 데이터에 나타나는 경관의 유형에 초점을 맞추었다. 따라서 해양경관이 포함된 ‘풍력발전시설 해양경관’과 육상경관이 포함된 ‘풍력발전시설 육상경관’으로 구분하였다.
두 번째로 경관의 시거리에 따른 분할을 기준으로 선정하였다. 경관을 지각하고 반응하는데 시점과 대상 사이의 시거리는 매우 중요한 역할을 한다. 이에 시거리 분할에 관한 선행연구 고찰을 통해 대상물에 따른 근경, 중경, 원경 분류를 확인하였다. 이 분류기준을 통해 풍력발전시설은 자연환경이나 인간의 특징으로 구분하기보다 건축물의 특징을 바탕으로 구분해야 한다고 판단했다. 따라서 풍력발전시설 경관의 근경역은 풍력발전시설이 독립적이고 상세하게 인식 가능한 영역으로 중경역은 시설군이 경관의 일부로서 인식되는 영역, 원경역은 시설이 군집 형태로 나타나며 지형의 형태나 스카이라인이 더 돋보이는 영역으로 구분하여 연구를 진행하였다.
세 번째로 경관의 선호를 기준으로 선정하였다. 경관의 선호는 경관의 좋고 나쁨을 뜻하는데 이를 연구자가 단독으로 판단하면 주관적인 개입으로 문제가 따른다. 따라서, 관련 분야 전공자를 대상으로 학습데이터 396장의 선호를 알아보기 위한 설문을 진행하였다. 총 30명의 응답을 받았으며 산술평균값을 통하여 좋고 나쁨을 구분하였다.
이와 같은 평가 기준에 따라 학습데이터 396장을 분류했다. 학습데이터 구축 결과는 Table 3과 같다.
다음으로 평가데이터 선정을 진행했다. 평가데이터 선정에는 1차 정제를 거친 이미지 데이터 2,080장 중에서 학습데이터로 사용된 396장을 제외한 나머지 1,684장을 사용했다. 데이터분석 프로그램 오렌지의 ‘Data Sampler’ 기능을 활용하여 50장의 이미지 데이터를 무작위 추출하였다. 평가데이터의 수량은 머신러닝의 일반적인 학습데이터와 평가데이터의 비율인 8:2를 적용하여 이에 적합한 수량을 선정해 진행하였다(Park, 2019).
본 연구는 머신러닝에 활용되는 University of Ljubljana의 데이터분석 프로그램 오렌지 버전 3.33을 이용하여 앞서 진행한 학습데이터 정제 및 평가 기준에 따라 모델을 생성하였다. 생성 모델의 알고리즘은 지도학습 분류 모델에 활용되는 것 중 본 연구에 적합하다고 생각되는 kNN, SVM, Random Forest, Logistic Regression, Neural Network를 활용하였다.
본 연구에 적합한 알고리즘을 활용하여 평가 기준 3가지를 통합한 모델 생성 결과 평가 기준에 따른 12가지 분류 중 3개의 분류가 학습데이터의 수량 부족으로 인한 교차검증이 제대로 이루어지지 않아 오류가 발생했다. 교차검증이 제대로 이루어질 수 없어서 성능 수치도 아주 낮게 나타났다. 이처럼 평가 기준 3가지를 통합한 모델은 다층구조로 이루어져 학습데이터의 수량 부족에 따른 문제가 발생하였다. 해당 문제는 학습데이터의 부족으로 야기되었기 때문에 데이터 증강(data augmentation)을 통해 문제를 해결하고자 했다(Shorten and Khoshgoftaar, 2019). 소량의 학습데이터에서 야기되는 문제 해결을 위한 데이터 증강에는 다양한 방법이 있으며 그러한 다양한 방법을 활용하여 학습데이터가 늘어날수록 모델의 정확도를 높일 수 있다. 그러나, 본 연구에서는 기본적인 기하학적 변환(geometric transformations)의 수직축을 기준으로 좌우 뒤집기(vertical flipping)를 활용했다. 이는 경관을 대상으로 하는 연구이기 때문에 시점이나 관점이 변화되면 기존의 경관을 잃어버릴 수 있기 때문이다. 따라서, 데이터의 증강을 통한 수량은 많지 않지만 기존 데이터의 특성의 변화가 최소화된 방법을 사용하여야 한다(Zhang et al., 2020). 이에 따라 본 연구에서는 수직축을 기준으로 좌우 뒤집기(vertical flipping)만 이용하여 데이터 증강을 진행했다. 이를 통해 데이터 증강을 마친 학습데이터 792장을 활용하여 다시 모델을 생성했다. 이를 통해 학습데이터 부족으로 야기된 문제를 해결하고 성능 수치가 우수한 모델 생성이 가능했다.
다음으로 평가 기준별 별도 모델을 생성하였을 땐 학습데이터 부족에 따른 문제는 발생하지 않았다. 그러나 기준별 별도 모델의 경관 유형 기준 모델과 시거리 기준 모델은 성능 수치가 높게 나타났으나 선호 기준 모델은 낮은 성능 수치를 기록했다. 따라서, 평가 기준별 별도 모델도 성능 수치를 높여 예측 능력 향상을 위하여 데이터 증강을 진행했다. 앞선 3가지 평가 기준 통합 모델 생성과 같이 기하학적 변환(geometric transformations)의 좌우 뒤집기(vertical flipping)만 이용하여 데이터 증강을 진행했다.
데이터 증강을 마친 792장의 학습데이터를 활용하여 다시 모델을 생성했다. 이를 통해 성능 수치가 낮게 나타나던 선호 기준 모델의 수치가 높아졌으며 경관 유형 기준 모델과 시거리 기준 모델의 성능 수치도 향상되었다. 이에 따라 평가 기준별 별도 모델도 성능 수치가 우수한 모델 생성이 가능하였다.
본 연구에서 서술하고 있는 평가 기준별 통합 모델과 평가 기준별 별도 모델의 차이는 학습의 구조에 따라 구분이 된다. 평가 기준별 통합 모델의 경우 하나의 평가 데이터가 3가지 평가 기준이 다층구조로 이루어져 한번에 평가를 받는 구조로 이루어져 있으며, 평가 기준별 별도 모델의 경우 하나의 평가 데이터가 3가지 평가 기준이 개별적으로 모델을 구성하고 각각 평가를 받은 후 결과의 합으로 이루어져 있다. Figure 3은 모델 구조의 차이점을 보여주는 도식이다.
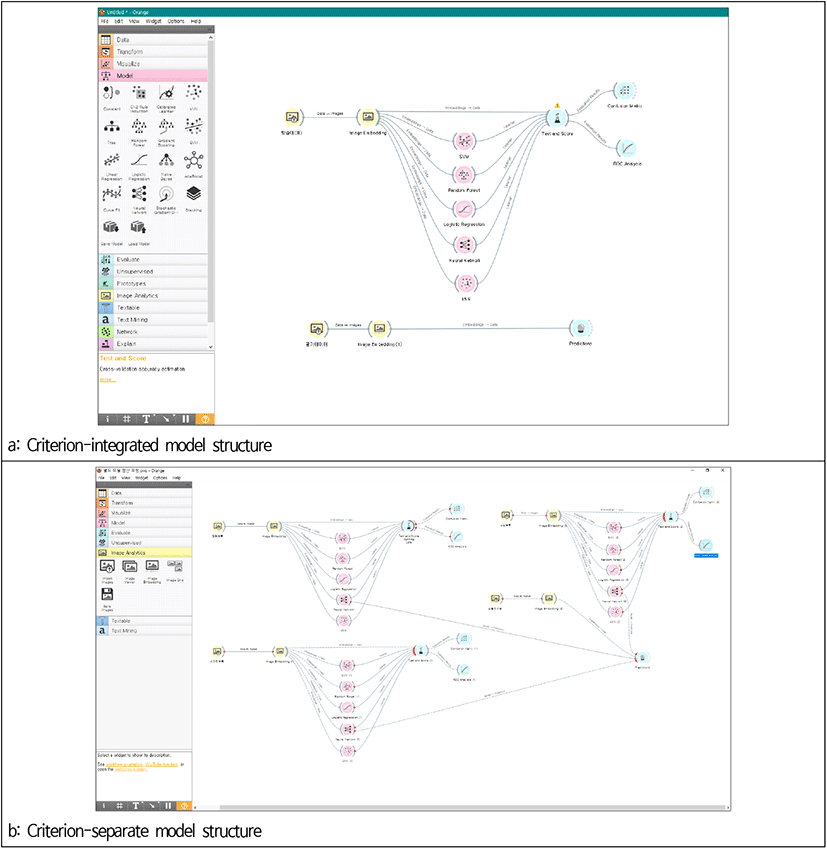
예측모델 생성 과정을 통해 도출된 모델은 기본 학습데이터를 통한 평가 기준 통합 모델, 데이터 증강을 통한 평가 기준 통합 모델, 기본 학습데이터를 통한 기준별 별도 모델, 데이터 증강을 통한 기준별 별도 모델 총 4개이다. 생성된 모델 중 본 연구에 가장 적합한 예측모델의 선정 과정을 수행하고자 모델의 성능평가를 진행하였다. 지도학습의 분류 모델 성능평가에는 혼동행렬(confusion matrix)이 기본적으로 사용된다. 이는 모델이 전체 데이터 중에서 어떤 부분을 얼마나 맞히고 틀렸는지에 대한 수를 표시한 매트릭스이다. 이를 통해 다양한 평가지표를 계산할 수 있다(aSSIST, 2021). 지도학습 분류 모델의 성능평가에 사용되는 지표는 AUC(area under the curve), CA(classification accuracy), F1, precision, recall, logloss가 있다. 본 연구의 예측모델 성능평가 또한 앞서 서술한 내용을 바탕으로 혼동행렬(confusion matrix)의 확인 및 ROC(receiver operating characteristic) Curve 그래프를 통한 AUC(area under the curve) 확인, 교차검증(cross-validation)을 통한 주요 지표 확인을 통해 모델 성능평가를 수행했다. 이러한 지표를 종합적으로 비교, 분석하였으며 평가지표 중 F1 수치와 logloss 수치를 선정의 중요지표로 판단했다(aSSIST, 2021).
기본 학습데이터를 통한 평가 기준 통합 모델은 성능평가 지표를 통해 선택된 SVM(support vector machine) 알고리즘의 F1 수치가 0.422, logloss 수치가 1.324로 매우 낮은 수치를 기록하였으며 혼동행렬과 산점도에서도 뚜렷한 기준선이 나타나지 않았다. 반면, 데이터 증강을 통한 평가 기준 통합 모델은 성능평가 지표를 통해 선택된 neural network 알고리즘의 F1 수치가 0.950, logloss 수치가 0.218로 매우 높게 나타났으며 혼동행렬과 산점도에서도 유의미한 기준선이 나타남을 알 수 있었다. 이처럼 지도학습 분류 모델에서 다층구조로 이루어진 모델에서 학습데이터의 부족이 유발하는 모델 성능 저하를 확인하였으며 데이터 증강 이후 우수한 성능평가를 받을 수 있음을 알 수 있었다. 다음으로 기본 학습데이터를 통한 기준별 별도 모델은 경관, 시거리, 선호 기준에 따른 모든 모델에서 SVM(support vector machine)이 우수 알고리즘으로 선택되었으며 F1 수치는 경관이 0.882, 시거리가 0.855, 선호가 0.690으로 나타났으며 logloss 수치는 경관이 0.253, 시거리가 0.323, 선호가 0.604로 나타났다. logloss 수치의 경우 모델이 전반적으로 양호함을 보여주고 있었으나 선호 기준 모델이 F1 수치가 높지 않아 정확도가 떨어지는 모습을 확인할 수 있었다. 이는 혼동행렬과 산점도에서도 확인할 수 있었다. 반면, 데이터 증강을 통한 기준별 별도 모델은 경관, 시거리, 선호 기준에 따른 모든 모델에서 neural network가 선택되었으며 F1 수치는 경관이 0.986, 시거리가 0.973, 선호가 0.952로 나타났으며 logloss 수치는 경관이 0.033, 시거리가 0.100, 선호가 0.126으로 나타났다. 해당 모델의 경우 F1 수치에 따른 정확도와 logloss에 따른 정답 선택 확신이 매우 높은 모델임을 알 수 있었다. 또한, 혼동행렬의 예측 정확도가 높아짐을 알 수 있었고 산점도에서도 분명한 구분과 오답의 양이 확연히 줄어든 것을 알 수 있었다.
이처럼 데이터 증강을 통한 기준별 별도 모델이 가장 좋은 성능평가를 받았으며 우수한 성능을 보여줌을 알 수 있었다. 이에 본 연구의 경관 지각 예측모델로서 데이터 증강을 통한 기준별 별도 모델을 선정하여 연구를 진행하였다. Table 4는 선정된 예측모델의 성능평가 지표를 정리한 것이다.
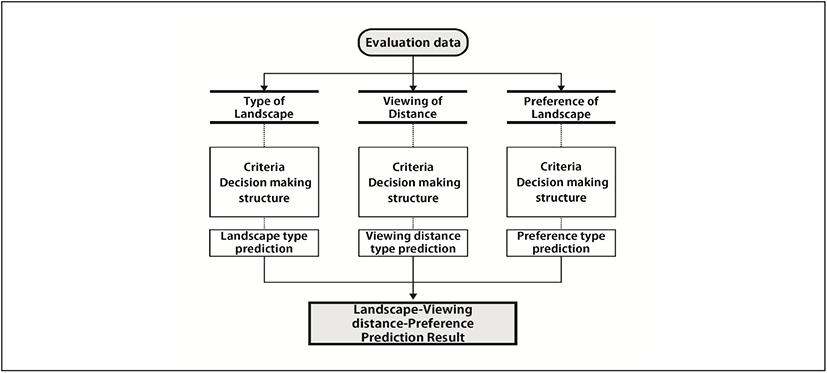
예측모델의 구조는 평가 기준에 따른 모델이 별도로 존재하며 예측을 진행할 때 3가지 모델의 평가를 각각 받도록 구성되어 있다. 즉, 평가 기준에 따른 모델은 별도의 의사 결정 구조를 가지고 있으며 평가데이터는 3번의 평가를 모두 받아서 결과를 예측하는 구조로 구성되어 있다. 예측모델의 구조는 Figure 4와 같다.
3. 결과 및 고찰
앞서 수행한 과정을 통해 확정된 풍력발전시설 경관 지각반응 예측모델을 통해 평가데이터 예측을 실행하였다. 도출된 예측 결과를 살펴보았을 때 본 연구의 예측모델의 3가지 평가 기준에 의한 평가를 모두 받았으며 이에 따라 결과가 도출되었다. 이를 통해 풍력발전시설 경관 지각반응 예측모델의 정상 구동을 확인할 수 있었다. 평가데이터는 총 50매이며 모델을 통한 예측 결과는 아래 Table 5와 같다.
본 연구를 통해 구현한 풍력발전시설 경관 지각반응 예측모델의 검증을 위해 예측 결과와 평가데이터를 비교 검증하였다. 비교 검증을 위해서 평가 기준에 따른 판단과 관련 전공자 30명을 대상으로 추가 설문을 진행하여 경관 선호를 조사하였다. 비교․검증의 결과 평가 경관 유형에 따른 모델에서는 오답이 하나도 없었으며 시거리에 따른 모델에서는 하나의 오답이 선호에 따른 모델에서는 두 개의 오답이 나타났다. Data No. 0653과 Data No. 0989는 학습데이터의 선호 기준과 검증 설문의 선호 판단에 차이가 나타나 오답을 선택한 것으로 판단되며, 다음 Data No. 1451의 경우 시거리에 따른 기준 판단에 오류가 나타났는데 이는 가까이 위치한 바람개비 조형물을 풍력발전기로 오인하여 발생한 것으로 생각된다. 이는 예측모델의 객체 인식 오류로 보인다. 이처럼, 총 50매의 평가데이터에서 오답으로 검증된 데이터는 3개로 나타났다. 오답으로 검증된 데이터의 예측내용과 검증내용의 비교는 Table 6과 같고 오류로 검증된 데이터는 Figure 5와 같다.

풍력발전시설 경관 지각반응 예측 결과를 통해 평가를 진행했다. 모델 성능평가 지표와 예측 결과를 바탕으로 도출된 혼동행렬(confusion matrix)을 활용한 지표를 비교하여 분석했다. 예측 결과 혼동행렬(confusion matrix)은Figure 6과 같다.
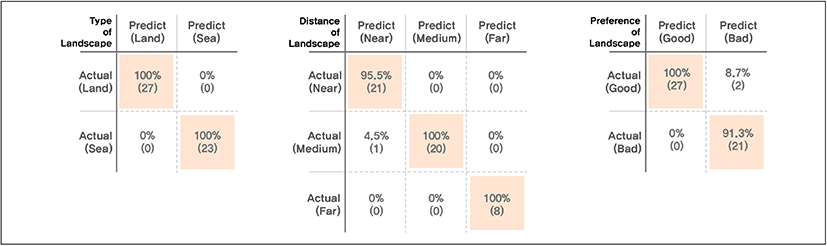
예측모델의 성능평가 지표와 예측 결과 도출 지표의 비교․분석을 통해 보았을 때 결과 도출 지표의 수치가 예측모델 성능보다 상회하고 있음을 알 수 있다. 반면 선호 기준 모델의 precisiom 지표, ‘양성 진단 정확성’ 수치가 낮아졌는데 이는 평가데이터 예측 결과에서 오답의 빈도가 예측모델 성능보다 높기 때문으로 보인다. 하지만 앞서 예측모델의 선정 과정과 같이 종합적으로 판단하기 위해 F1 수치와 logloss 수치를 중요지표로 보고 판단하였다. 이에 따라, 예측모델의 성능평가 지표와 예측 결과 도출 지표의 F1 수치를 비교해 보았을 때, 예측모델 성능평가는 경관 유형에 따른 기준이 0.986, 시거리에 따른 기준이 0.973, 선호에 따른 기준이 0.952로 나타나고 예측 결과 도출 지표에서는 경관 유형에 따른 기준이 1, 시거리에 따른 기준이 0.980, 선호에 따른 기준이 0.955로 예측모델의 성능보다 좋은 결과를 얻었다고 판단된다. 또한, logloss 수치를 비교해 보면 예측모델 성능평가에서 경관 유형에 따른 기준이 0.033, 시거리에 따른 기준이 0.100, 선호에 따른 기준이 0.126으로 나타나고, 예측 결과 도출 지표에서는 경관에 따른 기준이 0, 시거리에 따른 기준이 0.03492, 선호에 따른 기준이 0.063213으로 예측모델의 성능보다 좋은 결과를 얻었다고 판단된다. 이처럼 풍력발전시설 경관 지각반응 예측 결과를 혼동행렬(confusion matrix)을 활용해 평가해본 결과 예측모델의 성능 이상의 성과를 도출했다고 판단된다. 아래 Table 7은 예측모델 성능평가 지표와 예측 결과 도출 지표의 비교를 나타낸다.
본 연구는 머신러닝을 활용하여 경관 지각반응 예측모델의 개발 가능성을 알아보고자 풍력발전시설 경관을 대상으로 선정하여 데이터를 수집하고 구축하여 모델을 생성하고 선정하였다. 이를 통해 경관 유형 평가 기준 정확도 0.986, 시거리 평가 기준 정확도 0.973, 선호 평가 기준 정확도 0.952에 달하는 높은 정확도를 가진 예측모델을 개발하였다. 평가데이터 예측 결과를 통한 검증과정을 보아도 모델의 성능치를 상회하는 성과를 도출했음을 알 수 있다. 이를 통해 머신러닝을 활용하여 경관 평가가 충분히 가능하다는 점을 확인하였다.
이는 조경학 분야 경관 관련 연구에서 머신러닝을 활용한 예측모델 개발 가능성을 알아본 실험적 시도로, 이미지 데이터의 수집 및 정제를 통해 데이터 세트를 구축하여 높은 성능의 예측모델이 생성 가능하며 이후 경관 관련 연구에 한정되지 않고 다양한 조경학 연구 분야에 활용될 수 있다는 가능성을 확인할 수 있었다. 또한, 다양한 대상에 적용이 가능한 머신러닝 기법을 활용하여 현재 활발히 진행되고 있는 텍스트 마이닝 기법의 과거 현상에 대한 추세를 통한 미래 예측의 어려움이 있다는 한계점을 보완하여 가치 있는 연구를 진행할 수 있다고 판단된다. 따라서, 텍스트 마이닝 기법과 머신러닝 연구방법을 상호보완적으로 활용한다면 보다 가치있는 연구방법이 도출될 것으로 생각된다. 덧붙여, 평가데이터마다 사전작업이 필요하지 않아 대량의 평가데이터 예측이 가능하며 빅데이터의 활용으로 연구 자료의 시간적, 공간적 제약을 완화할 수 있다. 또, 예측모델의 평가데이터 결과를 학습데이터로 수용한다면 기존의 예측모델 대비 성능 향상을 이룰 수 있으며 간편히 모델을 수정하고 변경할 수 있다는 데 큰 의의가 있다.
하지만 본 연구에서 활용한 데이터분석 프로그램 오렌지에 한정된 연구로 프로그램에서 제공하는 분석과정만 이용할 수 있다는 한계를 분명히 가지고 있으며, 이는 추가적인 머신러닝 기법 연구와 분석 도구 학습을 통해 극복해 나갈 수 있을 것으로 생각된다. 이에 실험적 시도로의 연구에 그치지 않고 후행 연구를 진행하여 조경학 분야의 연구 범위 확대 및 기술 발전에 따른 새로운 연구 방법론 개발에 기여하는 데 학문적으로 큰 의미가 있다.
4. 결론
머신러닝을 활용한 경관 지각반응 예측모델 개발 가능성 연구를 요약하면 아래의 내용과 같다.
-
머신러닝 기법의 조경학 분야 적용 가능성을 알기 위해 연구를 수행하였으며 다양한 조경학 연구 대상 중 경관을 대상으로 진행하였다. 특히, 경관의 평가 가능성을 알아보고 경관 지각반응 예측모델 개발을 위해 3가지 기준을 정립하였으며 그에 따른 데이터 세트 구축을 통해 경관 지각반응 예측모델을 구성하였다. 본 연구의 목적을 달성하기 위한 세부 대상으로는 풍력발전시설의 경관을 선정하였으며, 이는 이미지 데이터 수집이 용이하고 시설과 경관의 구분이 뚜렷하여 경관 평가를 위한 구성 요소 식별에 용이하다는 판단으로 머신러닝에 적합하다고 생각하였다.
-
경관에 따른 기준, 시거리에 따른 기준, 선호에 따른 기준 3가지 평가 기준을 토대로 모델을 생성하였으며 모델 오류 현상 해결 및 정확도 향상을 위하여 기본 학습데이터를 통한 평가 기준 통합 모델, 데이터 증강을 통한 평가 기준 통합 모델, 기본 학습데이터를 통한 기준별 별도 모델, 데이터 증강을 통한 기준별 별도 모델 총 4가지의 모델을 생성하였다. 생성한 모델의 알고리즘별 평가를 진행하였으며 각 모델의 가장 유의미한 알고리즘을 해당 모델의 알고리즘으로 선정하였다. 대표 알고리즘이 결정된 4가지 모델의 성능지표 비교·분석을 통한 모델선정이 이루어졌으며, 본 연구의 예측모델로는 데이터 증강을 통한 기준별 별도 모델이 성능평가 지표에서 우수한 수치를 나타내 선정되었다.
-
본 연구의 예측모델을 통해 평가데이터 예측을 실행한 결과 3가지 평가 기준에 의한 평가를 모두 받았으며 이에 따라 결과값이 나타났다. 이를 통해 풍력발전시설 경관 지각반응 예측모델의 정상 구동을 확인할 수 있었다.
-
예측모델의 예측 결과 타당성 검증을 위해 평가 기준 판단과정과 추가 설문조사를 통해 비교·분석 과정을 진행하였다. 이를 통해 평가데이터 50매 중 3장의 오답을 발견하고 오답의 이유를 유추해 보았다.
-
예측모델의 평가를 위해 모델 성능평가 지표와 예측 결과를 바탕으로 도출된 혼동행렬(confusion matrix)을 활용한 지표를 비교하여 분석했다. 예측모델의 성능평가 지표와 예측 결과 도출 지표의 F1 수치와 logloss 수치를 비교해 보았을 때 예측모델의 성능보다 좋은 결과를 얻었다고 판단된다. 이처럼 평가과정을 통해 살펴본 결과 예측모델의 성능 이상의 성과를 도출하였다.
본 연구는 기존의 경관 평가 연구들과는 다르게 머신러닝 기법을 활용하여 경관 평가를 진행할 수 있는지에 대한 가능성 확인과 실제 연구 대상으로 풍력발전시설 경관을 선정하여 모델의 개발과 검증 및 평가를 통해 조경학 분야의 연구 방법론으로 가치를 확인하고 조경학 분야 연구영역의 확대에 기여할 수 있다는 점에서 큰 의의가 있다. 기존의 연구 방법에 비해 효율적인 측면에서 많은 이점을 가지고 있으며 빅데이터의 활용으로 연구의 시간적, 공간적 제약을 완화할 수 있다. 또, 예측모델의 확장과 변형, 그리고 예측 성능의 개선이 가능하여 연구에 큰 도움이 될 것으로 판단된다.
본 연구의 수행 과정과 결과를 통해 도출한 시사점은 다음과 같다.
경관 유형에 따른 평가 기준 정확도 0.986, 시거리에 따른 평가 기준 정확도 0.973, 선호에 따른 평가 기준 정확도 0.952에 달하는 높은 정확도를 가진 예측모델을 개발하였으며 평가데이터 예측 결과를 통한 검증과정을 보아도 모델의 성능 치를 상회하는 성과를 도출했음을 알 수 있다. 경관 관련 연구에서 머신러닝을 활용한 예측모델 개발 가능성을 알아본 실험적 시도로 이미지 데이터의 수집 및 정제를 통해 데이터 세트를 구축하여 높은 성능의 예측모델이 생성 가능하며, 이후 경관 관련 연구 분야에 활용될 수 있다는 가능성을 확인할 수 있었다. 또한, 국가적 차원의 인공지능 학습데이터 조성 정책에 따라 빅데이터 활용을 통한 다양한 연구주제의 설정이 가능하다. 본 연구는 인공지능 분야 중 머신러닝의 지도학습에서 분류모델을 활용하였지만 비지도학습, 강화학습 등 다양한 학습방법을 활용할 수 있으며 나아가 딥러닝 등의 다른 인공지능 방법론의 조경학 분야 연구 적용 가능성이 열려 있음을 알 수 있었다.
이와 같은 시사점을 통해 머신러닝을 활용한 경관 평가 예측은 물론 조경학 분야에서 다양한 주제와 방법론을 활용한 후속 연구가 이루어질 수 있다. 하지만 본 연구는 머신러닝을 활용하여 경관 평가 예측을 수행한 첫걸음으로 많은 한계점을 가진다. 먼저 학습데이터를 통해 판단기준을 설정하고 이에 따른 부합한 선택을 내리게 되는 머신러닝은 학습데이터의 품질과 양에 따라 모델의 정확도가 변화하는 기술적인 한계점을 가진다. 이러한 기술적 한계를 극복하는 다양한 방법들이 연구되고 있지만, 경관의 시점이나 관점이 중요시되는 조경학 분야에서 적용할 수 있는 방법론은 한정적이다. 그리고 판단을 학습된 기계에 위임하는 형태이기 때문에 본 연구에서와 같이 판단기준을 오판하거나 객체 인식에 오류가 생기는 등 기술적 한계점을 가진다. 이러한 한계점은 향후 머신러닝의 기술적 발전이나 보다 진보된 딥러닝을 활용하는 추가 연구가 필요할 것으로 생각된다. 또한, 본 연구는 머신러닝 기법의 경관 평가 가능성을 알아보고 실제 대상에 적용 가능한지 여부를 고찰하기 위한 기초 연구로 예측 평가 결과를 통해서 풍력발전시설 경관에 대해 분석하고 해석하여 판단하기에는 어려움이 있다. 즉, 풍력발전시설 경관을 명확하게 판단해주는 일반적인 평가로 보기에는 어렵다. 그러나 경관 평가의 기준이 되는 요인의 특정, 인자의 분석이 더불어 이루어진다면 체계적이고 합리적인 평가 방법이 될 수 있음을 알 수 있다.
앞서 도출한 시사점과 한계점을 반영하여 풍력발전시설의 경관뿐만 아니라 자연경관이나 문화경관 등 다양한 형태의 경관 예측모델 개발이 가능할 것으로 생각되며, 경관 유형에 따라 이미지를 분류하는 모델의 연구를 통해 데이터 분류의 시간을 단축하거나 머신러닝을 활용한 경관예측 인자분석을 통해 경관계획 요소의 중요도 분석 등의 후속 연구를 진행한다면 조경학 분야에서도 머신러닝 기법을 보다 유용하고 가치 있게 활용할 수 있을 것으로 사료된다.